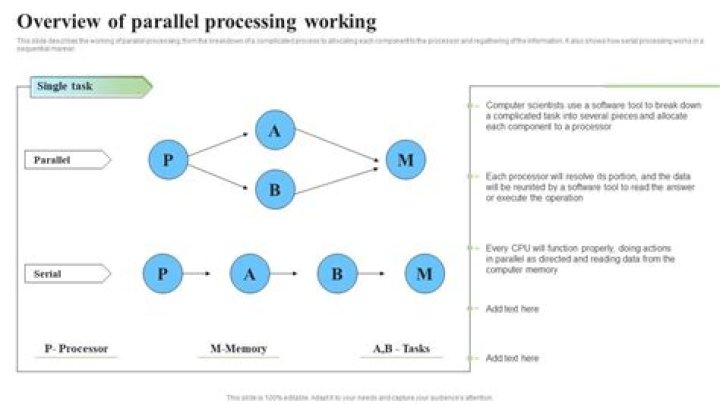
What is parallel processing in Hadoop?

John Thompson
Published May 15, 2026
Also to know is, what is parallel processing in big data?
Parallel computing may mean computing parallely among different CPU in the same machine but distributed computing takes it to a different level and runs on different machines at the same time and acts upon a subset of data by leveraging RAM and Disk space.
Furthermore, what is parallel computing used for? Parallel computing is a type of computation in which many calculations or the execution of processes are carried out simultaneously. Specialized parallel computer architectures are sometimes used alongside traditional processors, for accelerating specific tasks.
Considering this, how is MapReduce data parallel?
The Map function is applied in parallel to every pair (keyed by k1 ) in the input dataset. This produces a list of pairs (keyed by k2 ) for each call. After that, the MapReduce framework collects all pairs with the same key ( k2 ) from all lists and groups them together, creating one group for each key.
How is Hadoop different from other parallel computing systems?
Hadoop is a distributed file system, which lets you store and handle massive amount of data on a cloud of machines, handling data redundancy. On the contrary, in Relational database computing system, you can query data in
Related Question Answers
What is an example of parallel processing?
Parallel processing is the ability of the brain to do many things (aka, processes) at once. For example, when a person sees an object, they don't see just one thing, but rather many different aspects that together help the person identify the object as a whole.What is parallel processing and its advantages?
Advantages. Parallel computing saves time, allowing the execution of applications in a shorter wall-clock time. Solve Larger Problems in a short point of time. Compared to serial computing, parallel computing is much better suited for modeling, simulating and understanding complex, real-world phenomena.What do you mean by parallel processing?
Parallel processing is a method of simultaneously breaking up and running program tasks on multiple microprocessors, thereby reducing processing time. Parallel processing may be accomplished via a computer with two or more processors or via a computer network. Parallel processing is also called parallel computing.What are the type of parallel systems?
The three models that are most commonly used in building parallel computers include synchronous processors each with its own memory, asynchronous processors each with its own memory and asynchronous processors with a common, shared memory.What is parallel processing in the brain?
In psychology, parallel processing is the ability of the brain to simultaneously process incoming stimuli of differing quality. Parallel processing is a part of vision in that the brain divides what it sees into four components: color, motion, shape, and depth.What is distributed computing in big data?
Distributed Computing together with management and parallel processing principle allow to acquire and analyze intelligence from Big Data making Big Data Analytics a reality. Different aspects of the distributed computing paradigm resolve different types of challenges involved in Analytics of Big Data.Does Google use MapReduce?
Google Dumps MapReduce in Favor of New Hyper-Scale Analytics System. Google has abandoned MapReduce, the system for running data analytics jobs spread across many servers the company developed and later open sourced, in favor of a new cloud analytics system it has built called Cloud Dataflow.What is the MapReduce algorithm?
MapReduce is a Distributed Data Processing Algorithm introduced by Google. MapReduce algorithm is useful to process huge amount of data in parallel, reliable and efficient way in cluster environments. It divides input task into smaller and manageable sub-tasks to execute them in-parallel.What is MAP reduce technique?
MapReduce is a processing technique and a program model for distributed computing based on java. The MapReduce algorithm contains two important tasks, namely Map and Reduce. Map takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs).What is MapReduce example?
An example of MapReduce The city is the key, and the temperature is the value. Using the MapReduce framework, you can break this down into five map tasks, where each mapper works on one of the five files. The mapper task goes through the data and returns the maximum temperature for each city.Where is MapReduce used?
Short answer: We use MapReduce to write scalable applications that can do parallel processing to process a large amount of data on a large cluster of commodity hardware servers. Not so Short answer: MapReduce was introduced by Google to meet the demand of their large set of users for its applications like- search etc.What is reduction in Parallel Computing?
In computer science, the reduction operator is a type of operator that is commonly used in parallel programming to reduce the elements of an array into a single result. Other parallel algorithms use reduction operators as primary operations to solve more complex problems.Is MapReduce a programming language?
MapReduce is a programming model to perform distributed and parallel processing. MapReduce can be written in Java, Python, etc. Though Hadoop is written in java but you can write MapReduce in any language you feel comfortable.What is the use of MapReduce in Hadoop?
Hadoop MapReduce (Hadoop Map/Reduce) is a software framework for distributed processing of large data sets on compute clusters of commodity hardware. It is a sub-project of the Apache Hadoop project. The framework takes care of scheduling tasks, monitoring them and re-executing any failed tasks.Who invented MapReduce?
Google MapReduce: Apache Hadoop To solve this, Google invented a new style of data processing known as MapReduce to manage large-scale data processing across large clusters of commodity servers. MapReduce is a programming model and an associated implementation for processing and generating large data sets.What are the disadvantages of parallel processing?
DISADVANTAGES: There is always an overhead associated with parallel processing.- The architecture for parallel processing OS is a bit difficult.
- Clusters are formed which need specific coding techniques to get rid of.
- Power consumption is high due to multi-core architecture.