Why do we preprocess data in data mining?

James Williams
Published Apr 09, 2026
Likewise, people ask, why do we preprocess the data?
It is a data mining technique that transforms raw data into an understandable format. Raw data(real world data) is always incomplete and that data cannot be sent through a model. That would cause certain errors. That is why we need to preprocess data before sending through a model.
Similarly, how do you preprocess a data set? There are seven significant steps in data preprocessing in Machine Learning:
- Acquire the dataset.
- Import all the crucial libraries.
- Import the dataset.
- Identifying and handling the missing values.
- Encoding the categorical data.
- Splitting the dataset.
- Feature scaling.
Regarding this, why do we need to preprocess data in Machine Learning?
Data preprocessing is an integral step in Machine Learning as the quality of data and the useful information that can be derived from it directly affects the ability of our model to learn; therefore, it is extremely important that we preprocess our data before feeding it into our model.
Why do we clean data?
Data cleansing is also important because it improves your data quality and in doing so, increases overall productivity. When you clean your data, all outdated or incorrect information is gone – leaving you with the highest quality information.
Related Question Answers
Is it necessary to preprocess data?
Data preprocessing is crucial in any data mining process as they directly impact success rate of the project. Data is said to be unclean if it is missing attribute, attribute values, contain noise or outliers and duplicate or wrong data. Presence of any of these will degrade quality of the results.How do you handle noisy data?
The simplest way to handle noisy data is to collect more data. The more data you collect, the better will you be able to identify the underlying phenomenon that is generating the data. This will eventually help in reducing the effect of noise.What are the major issues of data mining?
Some of the Data mining challenges are given as under:- Security and Social Challenges.
- Noisy and Incomplete Data.
- Distributed Data.
- Complex Data.
- Performance.
- Scalability and Efficiency of the Algorithms.
- Improvement of Mining Algorithms.
- Incorporation of Background Knowledge.
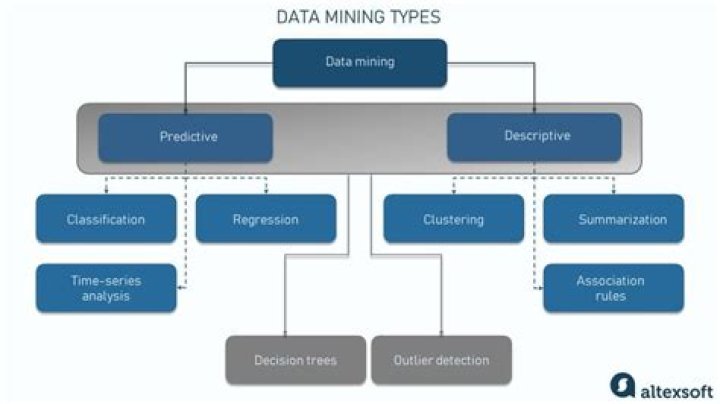
What are the data mining techniques?
16 Data Mining Techniques: The Complete List- Data cleaning and preparation.
- Tracking patterns.
- Classification.
- Association.
- Outlier detection.
- Clustering.
- Regression.
- Prediction.
Why data preparation is so important?
Data preparation ensures accuracy in the data, which leads to accurate insights. Without data preparation, it's possible that insights will be off due to junk data, an overlooked calibration issue, or an easily fixed discrepancy between datasets.How important is data in deep learning?
Another most important role of training data for machine learning is classifying the data sets into various categorized which is very much important for supervised machine learning. It helps them to recognize and classify the similar objects in future, thus training data is very important for such classification.What causes noise in data?
Noisy data can be caused by hardware failures, programming errors and gibberish input from speech or optical character recognition (OCR) programs. Spelling errors, industry abbreviations and slang can also impede machine reading.Why is data important in ML?
On a predictive modeling project, machine learning algorithms learn a mapping from input variables to a target variable. The most common form of predictive modeling project involves so-called structured data or tabular data.What is cluster algorithm?
Cluster analysis, or clustering, is an unsupervised machine learning task. It involves automatically discovering natural grouping in data. Unlike supervised learning (like predictive modeling), clustering algorithms only interpret the input data and find natural groups or clusters in feature space.What are the steps in data cleaning?
How do you clean data?- Step 1: Remove duplicate or irrelevant observations. Remove unwanted observations from your dataset, including duplicate observations or irrelevant observations.
- Step 2: Fix structural errors.
- Step 3: Filter unwanted outliers.
- Step 4: Handle missing data.
- Step 5: Validate and QA.